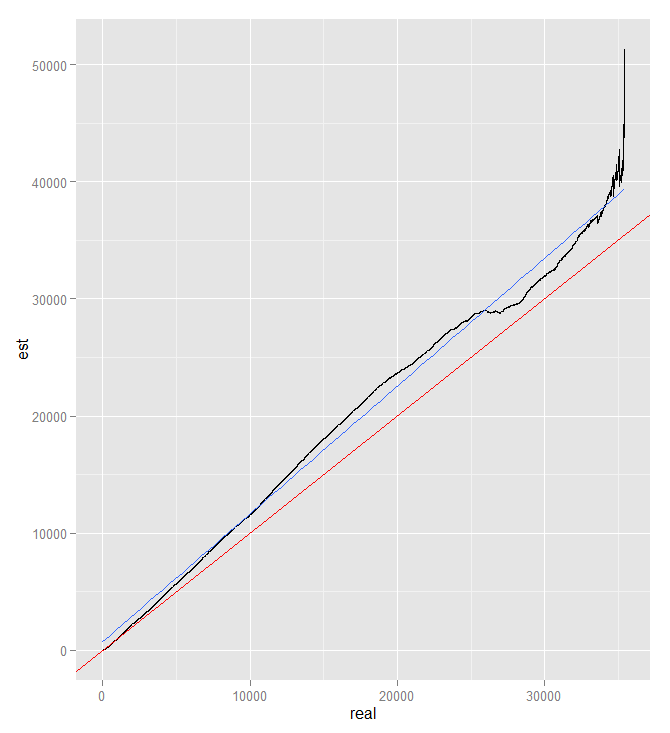
In a current project I tried to implement a method to estimate the time until the program finishes. My first approach was to use the last 32 processed items and there corresponding time to process, calculate an average and multiply it by the items still to process. Now I'm just using the averge time from all the last samples and multiply it by the number of samples to do.
As you can see in the plot it is relativly good, but could be better... The red line is the optimal curve, the blue the linear interpolated data from the real estimation (black). Units in the plot are seconds.